Uncertainty-Aware Language Modeling for Selective Question Answering
Presenting uncertainty-aware LLMs capable of estimating uncertainty with every prediction.
Abstract
We present an automatic large language model (LLM) conversion approach that produces uncertainty-aware LLMs capable of estimating uncertainty with every prediction. Our approach is model- and data-agnostic, is computationally-efficient, and does not rely on external models or systems. We evaluate converted models on the selective question answering setting — to answer as many questions as possible while maintaining a given accuracy, forgoing providing predictions when necessary. As part of our results, we test BERT and Llama 2 model variants on the SQuAD extractive QA task and the TruthfulQA generative QA task. We show that using the uncertainty estimates provided by our approach to selectively answer questions leads to significantly higher accuracy over directly using model probabilities.
Introduction
Large-language models (LLMs) have demonstrated great abilities in natural language tasks, including question answering (QA) wherein the model receives a question as input and outputs a response answer. The QA task is a fundamental component in many LLM applications. However, in order to robustly answer questions accurately, the model must understand context and ground its outputs in knowledge obtained from training data, which will typically contain conflicting information. Indeed, it has been shown that LLMs commonly fail in QA tasks (Geiger et al. 2019), and that these failures are associated with a limited understanding of output confidence, out-of-domain data, ambiguity in input prompts, inconsistent training information, and hallucinations, among others. Selective prediction(El-Yaniv et al. 2010; Geifman and El-Yaniv 2017), i.e., calculating confidence estimates along with predictions to forgo outputs likely to be incorrect, can be used to mitigate some of these issues.
Several approaches utilize the selective prediction to guide question answering tasks (Peñas et al. 2010; Gondek et al. 2012) and generally abstain from answering questions when output confidence is low. The objective is to maintain a given accuracy while answering as many questions as possible, as opposed to the more conventional goal of attempting to answer all questions correctly. One approach used inferred softmax classifier probabilities to calibrate which questions to respond to (Rodriguez et al. 2021). However, training a calibration model is challenging and softmax classifiers are often unreliable (Guo et al. 2017). Similarly, an out-of-domain (OOD) calibrator can be trained to detect OOD inputs (Kamath, Jia, and Liang 2020) but requires known or synthetic out-of-domain samples and does not consider other sources of inaccuracies like over-represented features or ambiguous labels. Other approaches include modeling and estimating LLM uncertainty (Dong, Quirk, and Lapata 2018; Shen et al. 2022; Chen and Mueller 2023; Lin, Trivedi, and Sun 2023; Collins et al. 2023; Chuang et al. 2023; Quach et al. 2023), fine-tuning calibrators to consider entropy, perplexity, and other metrics (Jiang et al. 2021), and calculating output consistency (Manakul, Liusie, and Gales 2023; Miao, Teh, and Rainforth 2023). Another family of techniques retrieve evidence and verify outputs through external databases (Guo, Schlichtkrull, and Vlachos 2022) or in-context learning (Weng et al. 2022). These solutions require the development of knowledge bases and efficient querying systems which are often not practical and fundamentally limited by the information that exists. A facile, performant, and efficient way to estimate uncertainty directly from models, without the need of external components, is needed to design a general selective question answering framework that is applicable to a wide range of tasks.
We present an uncertainty-based framework for selective QA that accounts for epistemic and aleatoric uncertainty. We consider both extractive and generative LLM models e.g., masked-language models and autoregressive models respectively, and implement and evaluate a suite of uncertainty quantification (UQ) methods spanning these uncertainty types. We find that while the individual methods significantly increase performance on the selective QA task, it is the combination of methods and metrics that yield the best accuracy. Leveraging this observation and seeking to enable both performance and efficiency, we present an approach to automatically convert LLMs into uncertainty-aware variants and to compose metrics and methods automatically. Our approach is model- and data-agnostic, lightweight, and does not rely on external models or systems.
Methodology
Selective Question Answering
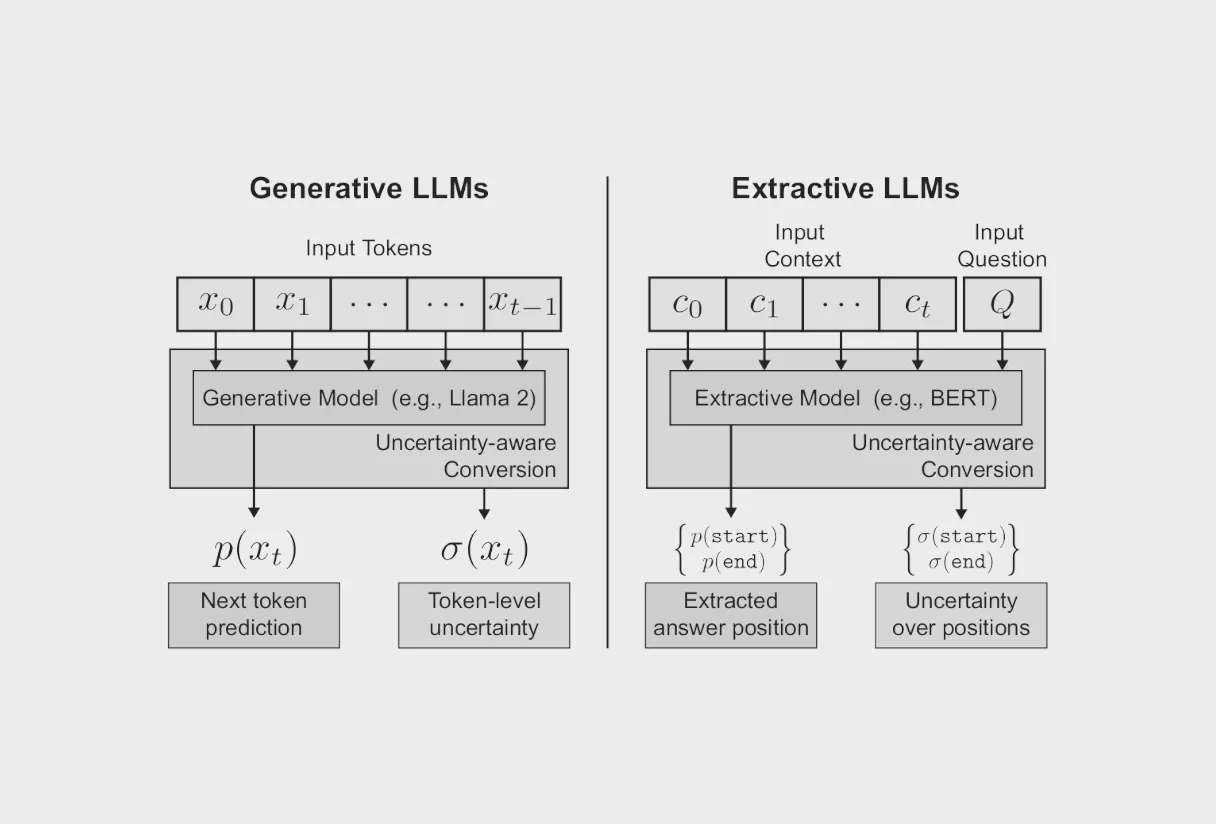
Given an input prompt , the question answering task is to output a prediction where , the set of all possible responses, that correctly answers the question. In the selective QA task, the model also outputs , an uncertainty estimate for a given output , where . Given a threshold , the model outputs if and refrains from responding if this condition is not met. Each value results in quantities for coverage (i.e., the ratio of questions the model chose to respond to), and accuracy, (i.e., the number of predictions that correctly answer the question). The goal is to maximize the number of questions that can be answered accurately, that is, to increase both coverage and accuracy. In this work, we convert models into uncertainty-aware variants that output aleatoric, epistemic, or composed uncertainty estimates for every prediction. The model learns data-dependent thresholds and outputs answers where . It forgoes providing responses to questions where no candidate with this requirement exists.
Models and Datasets
Extractive models and dataset In the extractive question answering task (Wang et al. 2006), each input represents which is composed of context text and a question . The space of possible answer candidates is all sequential segments in as defined by start and end indices within with each index representing a token in the text. We consider the SQuAD datasets (Rajpurkar et al. 2016; Rajpurkar, Jia, and Liang 2018), a collection of over one hundred of thousand questions with corresponding answers presented as segments from passages of text. We use BERT (Devlin et al. 2018), more specifically bert-base-uncased 108M with the WordPiece Tokenizer (Wu et al. 2016), as our base model to define probability distributions over . We convert this model into an uncertainty-aware variant that outputs uncertainty for each index in the context text for every prediction.
Generative models and dataset In the generative question answering task, input prompts are composed of sequences of tokens representing questions. A model is used to incrementally predict each subsequent token, starting from the last token in the input prompt, to compose a response that correctly answers the question. The space of answer candidates includes all possible sequential combinations of tokens in a given vocabulary. We consider the TruthfulQA question answering benchmark (Lin, Hilton, and Evans 2021), 817 questions divided into several categories, meant to represent questions commonly answered incorrectly by humans and therefore likely to be learned by models imitating human text. We use Llama 2 (Touvron et al. 2023), more specifically Llama 2-Chat 7B, which has been fine-tuned for dialogue use cases with a vocabulary of 32k tokens, as our generative model. We convert this model into an uncertainty-aware variant that outputs uncertainty estimates for the entire vocabulary for every predicted token.

Model training and evaluation Our extractive model, bert-base-uncased, is pre-trained on Book Corpus (Zhu et al. 2015) and Wikipedia (Devlin et al. 2018). We further train for 3 epochs on the 130,319 training samples provided in the SQuAD 2.0 dataset (Rajpurkar, Jia, and Liang 2018). The uncertainty-aware variants are created by converting the pre-trained model before training. We evaluate all models on the 11,873 questions in the SQuAD 2.0 test set, reporting accuracy for Exact Match and F1 metrics. We use the NeMo framework (Kuchaiev et al. 2019) to train and evaluate our models. Our generative model, Llama 2-Chat 7B, is pre-trained and fine-tuned for dialogue use cases. The uncertainty-aware variant is created by converting this version of the model directly. No further training or modifications are performed. We report accuracy using the BLEURT metric (Sellam, Das, and Parikh 2020).
Uncertainty Methods and Metrics
The uncertainty-aware model conversion produces a new model that is able to estimate multiple different types of uncertainty, which we discuss in the following section.
Aleatoric uncertainty captures incertitude resulting from data (e.g., irreducible noise, labeling errors, classes with low separation, etc). It quantifies what a model cannot understand given the data provided. We model aleatoric uncertainty using Mean and Variance Estimation (MVE) (Nix and Weigend 1994). In regression, a layer predicts model output deviations and is trained using a negative log-likelihood loss. An algorithm that generalizes to the classification case is given below. We assume the logits are drawn from a normal distribution and stochastically sample from them using the reparameterization trick. We average stochastic samples and backpropagate using cross entropy loss through logits and their inferred uncertainties.
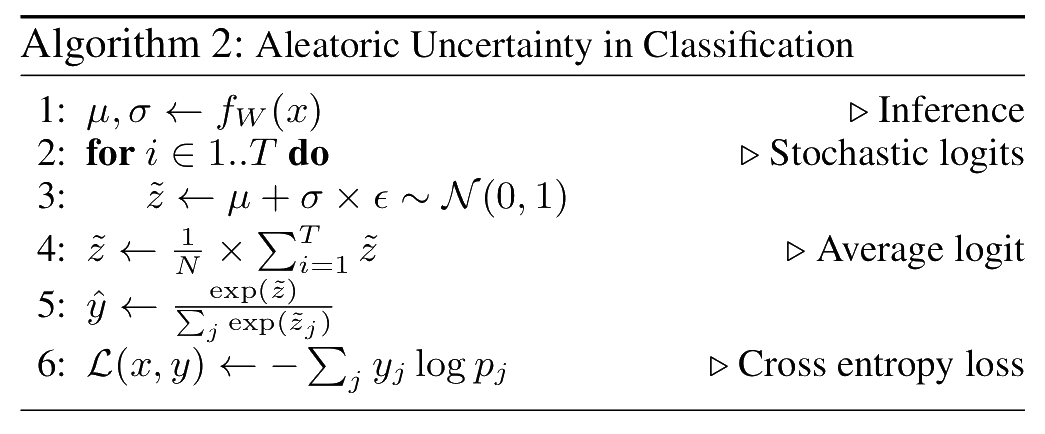
Epistemic uncertainty captures uncertainty arising from the predictive process. It quantifies the inherent limitations in the model or lack of knowledge, intuitively representing what the model does not know. We provide a unified approach for a variety of epistemic uncertainty methods.
A Bayesian neural network can be approximated by stochastically sampling, during inference, from a model with probabilistic layers (Blundell et al. 2015; Gal and Ghahramani 2016). Similarly, models of arbitrary depth that follow sampling-based procedures to temporarily remove units (Srivastava et al. 2014) from all layers are equivalent to approximations to the probabilistic deep Gaussian process (Damianou and Lawrence 2013) and can be used to estimate predictive uncertainty (Gal and Ghahramani 2016; Lemay et al. 2022; Mobiny et al. 2021). We calculate epistemic uncertainty using Monte Carlo sampling (MC), i.e., running stochastic forward passes and computing the first and second moments from these samples, yielding predictions and uncertainty estimates, respectively. Ensembles of models, each a randomly initialized stochastic sample, is another common approach used to estimate epistemic uncertainty (Lakshminarayanan, Pritzel, and Blundell 2017), but incurs a significant, multiplicative computational cost.
Uncertainty-aware Model Conversion
Traditionally, models output predictions in the form of . Our method applies a conversion, , to build an uncertainty-aware model to measure uncertainty metrics :
where is the estimated uncertainty. Our conversion procedure adds and modifies relevant model components while preserving structure and function. This allows the new model to serve as a drop-in replacement that is additionally able to estimate uncertainty metrics. All modifications are integrated into a custom, metric-specific forward pass and training step that integrates during training and inference. We use the Capsa framework (Lolla et al. 2022, 2023) to perform model conversions. We refer readers to the Capsa software library (Amini et al. 2023) for information on the software with the functionality described in this publication.
Results
In this section we present results for conventional and uncertainty-guided selective question answering. We use our conversion procedure to automatically create uncertainty-aware variants for several UQ metrics and evaluate in both extractive and generative QA tasks.
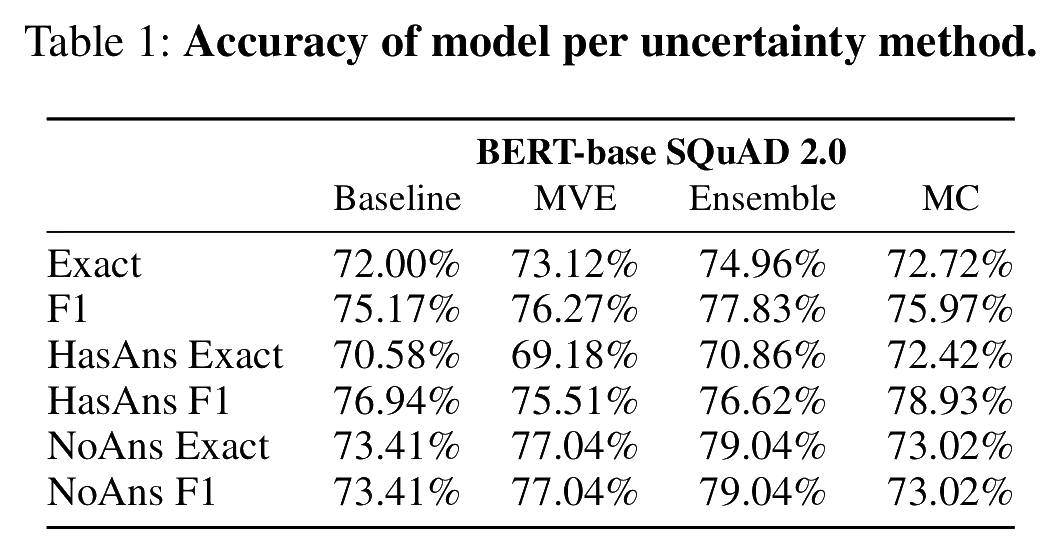
Nominal question answering performance For our initial evaluation we create MVE, MC, and Ensemble variants of our pre-trained extractive QA model. We train them for 3 epochs on the 130K samples provided in the SQuAD 2.0 dataset and collect Exact Match and F1 accuracy results for the 11K test questions. In Table 1 we find that the uncertainty-aware variants have performance that is consistent with the base model with no significant reductions in accuracy.
Uncertainty-guided selective question answering Having verified that QA performance remains consistent after model conversions, we compare the performance of the different UQ variants on the uncertainty-guided selective QA setting. For our extractive QA task, we evaluate models on the 5,928 answerable questions in the SQuAD test set. For the generative QA task, we generate multiple responses to all 817 questions in the TruthfulQA benchmark.
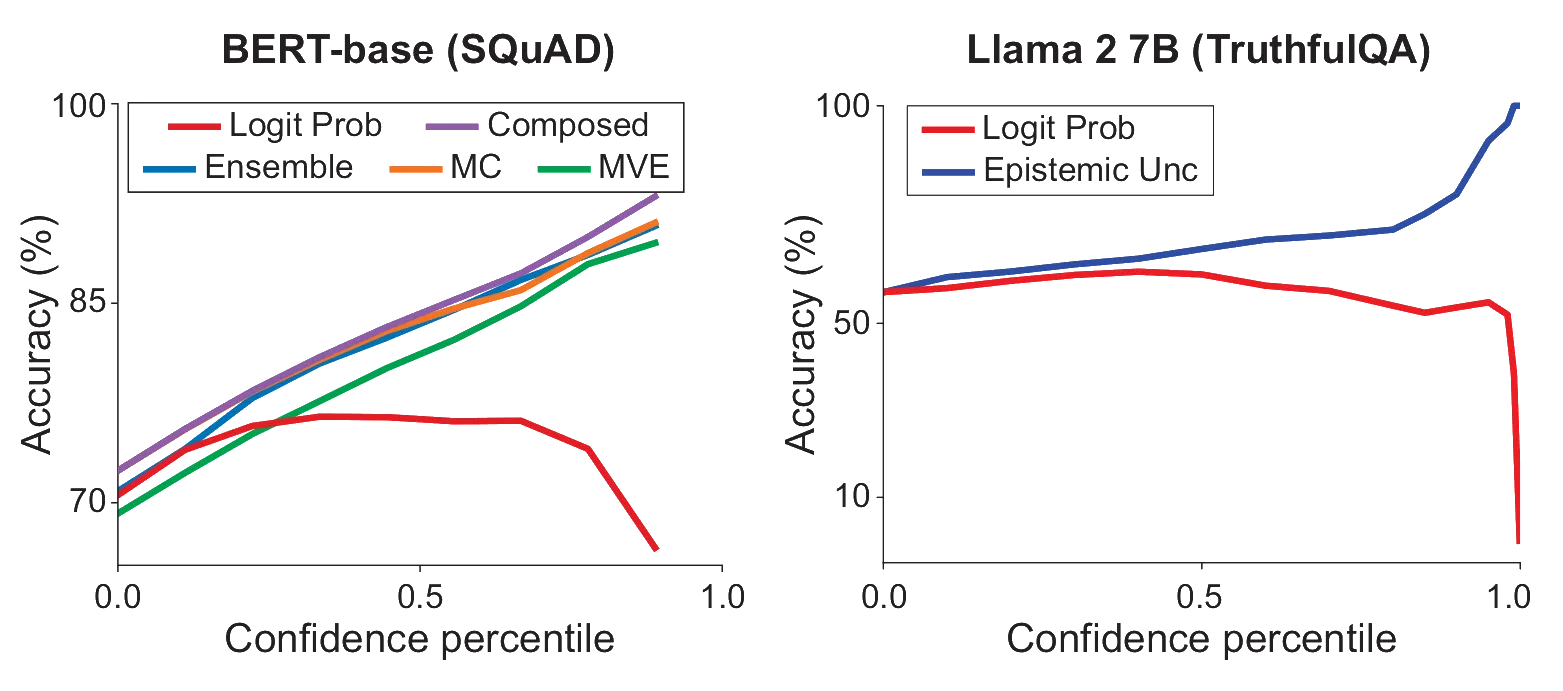
We compare the coverage and accuracy obtained by the MVE, Ensemble, and MC UQ variants when answering questions using their uncertainty estimates as the selective prediction criteria. We further compare the UQ variants to the original model, using the baseline logit probabilities (e.g., from softmax) as the confidence value to guide selective predictions. These results are outlined in the tables and figures below. Using UQ metrics as a measure of confidence leads to increased accuracy while answering larger portions of the questions, whereas using logit probability does not. More importantly, we observe that in both the extractive and generative case, predictions are least accurate when logit probability confidence is highest. In fact, performance gradually deteriorates to 0\% as confidence increases, indicating logit probabilities (e.g., from softmax) cannot reliably be used to determine answer confidence. Moreover, the highest performance achieved using logit probability, 76.50\% accuracy for 60\% of questions in the extractive case and 61.87\% accuracy for 60\% of questions in the generative case, is significantly lower than those achieved using UQ metrics.
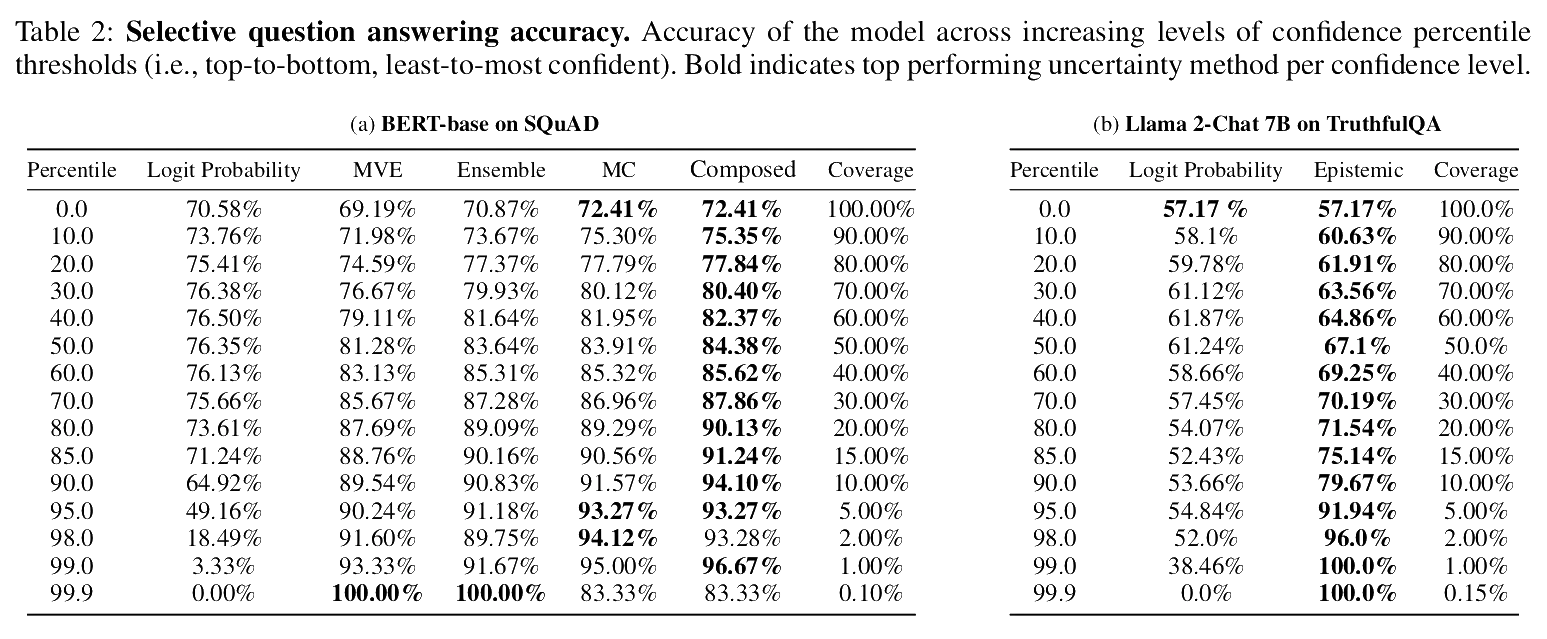
In the extractive case, MVE and Ensemble result in 100\% accuracy when answering questions in the top confidence percentile. MVE, Ensemble, and MC obtain +90\% accuracy with coverage rates of 5\%, 15\%, and 15\%, respectively, and +80\% accuracy with coverage rates of 50\%, 65\%, and 75\%, respectively. Ensemble is able to reach 100\% accuracy with the highest overall performance across all confidence levels. We observe that all converted models are able to consistently, throughout the entire set of questions, identify predictions likely to be incorrect (see Appendix).
In the generative case, using baseline logit probability to measure confidence leads to a maximum increase in accuracy of only 4.7\% for questions in the 4th lowest percentile. In comparison, our uncertainty-aware models are able to attain accuracy rates of 100\%, +90\%, +80\%, +70\% when answering 1\%, 8\%, 9\%, and 35\% of the questions, respectively, and result in higher accuracy across all confidence percentiles. We further observe that after generating 10 candidate answers for each question in the benchmark, answers with highest uncertainty were consistently incorrect. We also note that the converted model is able to output correct answers if it repeatedly generates predictions until one in the 99\% confidence percentile is found.
Table 3 outlines results relating to computational performance. We find the converted models incur minimal overhead in inference time and a negligible increase in number of parameters. However, the Ensemble variant, results in significant computational cost, roughly five times that of the original model. Our automatic uncertainty-aware conversion procedure is completed in 0.0994 seconds for the 108M model and in 1.3856 seconds for our 7B model.

Automated composition for performance and efficiency in selective QA The performance of our Ensemble models motivated us to leverage our automated conversion procedure to devise a compositional UQ method with strong accuracy that does not require the training of multiple independent models or incur significant computational costs. We hypothesized that considering both aleatoric and epistemic uncertainty would result in a more comprehensive UQ metric. We used MC as the epistemic uncertainty metric given that our experiments showed it to be more computationally efficient than Ensemble. We combined the measurement with MVE, which estimates aleatoric uncertainty, and used our conversion procedure to create a model that calculates this composed metric with every output. As shown in the tables and figures below, the composed approach attained significantly higher accuracy when compared to other independent UQ metrics. Importantly, the composed approach does not incur the significant computational overhead required by Ensembling-based approaches. Our results demonstrate that automated uncertainty-awareness enables the facile composition of different UQ methods to optimize for both performance and computational efficiency, and enables strong effectiveness on selective question answering tasks.
Conclusion
We present an uncertainty-based framework for selective question answering (QA). Our method automatically converts existing LLMs into an uncertainty-aware variant, capable of estimating different forms of uncertainty. We demonstrate an increase in empirical coverage and accuracy on selective QA across models ranging in size from 100M to 7B parameters.
Published as “Uncertainty-Aware Language Modeling for Selective Question Answering” (Yang et al., 2023).