Preliminary Steps Towards Risk-Aware Image Generation
Using Capsa to automatically evaluate the quality of images generated by Stable Diffusion

Preliminary Steps Towards Risk-Aware Image Generation


Overview
We share some preliminary progress wrapping existing generative models with Capsa to obtain epistemic uncertainty estimates during the generation process.
In this post, we consider a Keras implementation of Stable Diffusion, a latent text-to-image diffusion model. The image generator contains three main models which we wrap individually, i.e., (i) CLIP, a text encoder that takes in prompts as input (ii) the diffusion model, used to generate latents over multiple steps (iii) an autoencoder decoder, which converts latents into images.
Capsa is able to wrap models of multiple formats and to augment their output with risk estimates that are computed automatically using a model-agnostic algorithm. These estimates are provided via RiskTensors, an extended tensor which provides aleatoric, epistemic, and bias information along with standard output. This new information allows us to monitor the uncertainty encountered by these three models as they iterate to produce the final image.
The models considered are pre-trained. All outputs shared below were obtained by wrapping the models using existing weights. This process allows us to see epistemic risk estimates without altering the models or their output. We leave using Capsa to estimate representation bias and aleatoric uncertainty, and to train the risk-aware versions of these models for future work.
Diffusion
The diffusion model takes in token embeddings for the prompt, i.e., text description of what will be in the image, and processes that information in a latent space iteratively over 50 steps. The model typically outputs 64,64,4 latents at each step (shown in grey in the second column below). However, because we wrapped the model with Capsa we are able to automatically obtain epistemic risk values for each cell as well.
For each of the 50 steps we show: The output image obtained by decoding the latent at that step (first column), the latent produced by the diffusion model at that step (second column), a false-colored image of scaled epistemic risk values for each cell in the latent (third column), and the absolute (no scaling) epistemic risk values for each cell (fourth column). Note that the values shown in the third column are scaled using local minimum and maximum values. Matplotlib’s Magma colormap is used to generate the images in the third and fourth columns. Finally, we show contours around the top percentile risk regions above the animation on the top right.







A few examples of images with low estimated risk are below.


Processing Prompts
The text descriptions provided by the user, i.e., prompts, are processed by CLIP. This text encoder produces embedding vectors in a 768-dimensional space for each token in the prompt. We wrap a version of this model using Capsa and are able to automatically estimate epistemic uncertainty for each token in the prompt. Note that these estimates of uncertainty are produced before the image generation process begins. Therefore, they could be used to fine-tune text in prompts without having to go through the time consuming and computationally expensive process of exhaustively generating images for each one. We share some informal notes on using prompts with low epistemic uncertainty estimates in the Observations section.
Some examples of uncertainty estimates are below.
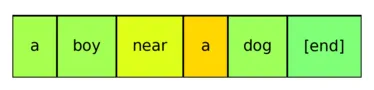
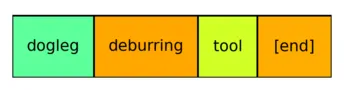






![]()
Decoding Latents
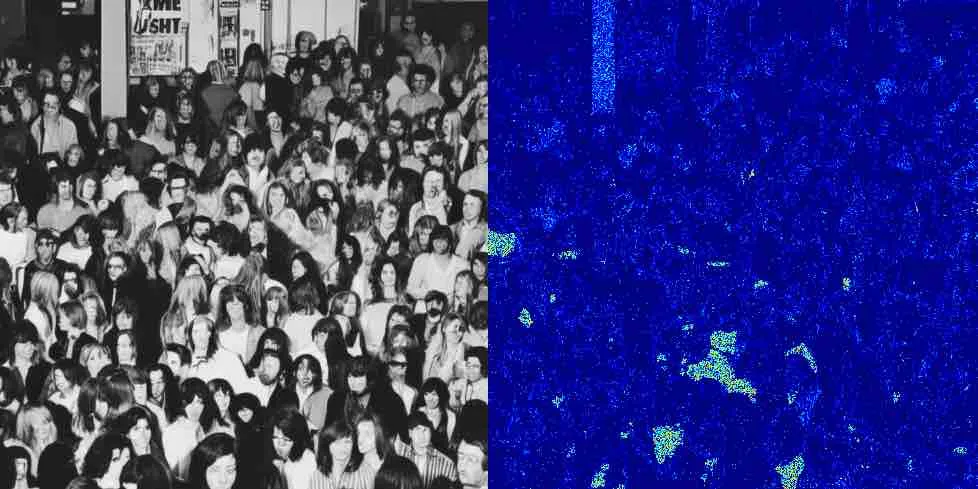
An autoencoder decoder with several ResNet, UpSampling2D and Conv2D layers takes in latents as input to produce the final 512x512 images. We wrap this decoder using Capsa in order to automatically calculate epistemic risk values for all areas in the resulting image. Decoding is the final step of the image generation process and takes place only once in the current implementation. However, it is possible to decode the latent at the end of each diffusion step in order to track progress (as we show above). Considering both decoding and diffusion risk at each step might provide promising information regarding the overall uncertainty encountered during the generation progress. We leave further explorations of this type for future work.
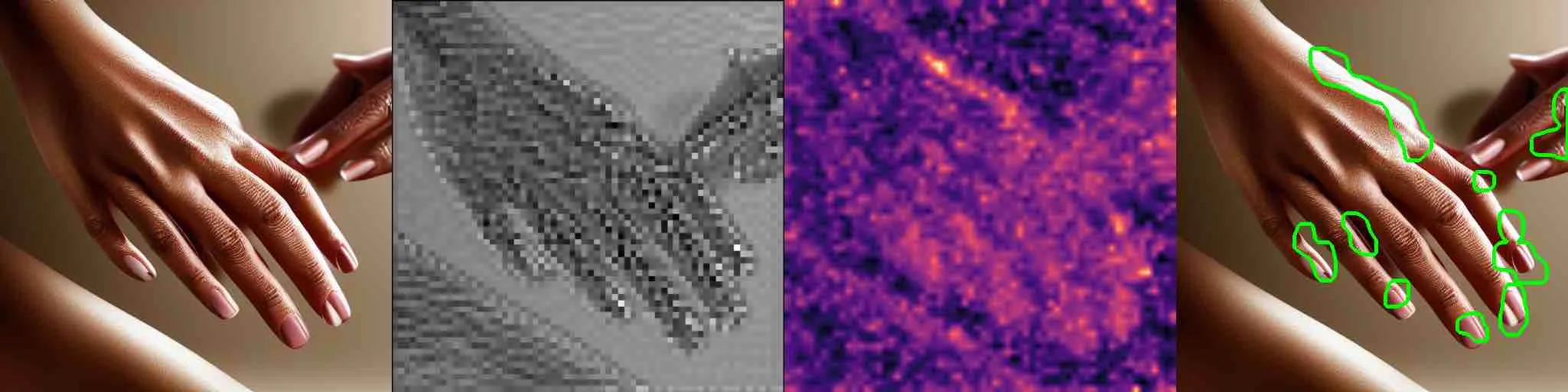
Some examples of decoding risk estimates for the final latents are below. We show the decoded images (left) along with the epistemic uncertainty values at each pixel (right).

Observations
Some observations related to our preliminary tests are below.
Hand Prompts
Accurately generating images featuring hands is a common challenge for image generators. As part of our preliminary tests with risk-aware generation, we explore fine-tuning prompts using text encoder epistemic uncertainty. Because being as descriptive as possible in prompts generally leads to better results, we employed a simple heuristic to score prompts that considered the epistemic uncertainty for each token with a small incentive for longer prompts. Our general approach was to informally add as much description as possible while considering how the combination and ordering of words, usage of punctuation, phrasing, and other aspects affected the uncertainty encountered by the encoder. Some of the prompts considered are listed below along with some images generated using the lowest and highest scoring prompts. We can see that lower risk prompts lead to slightly improved depictions of hands and fingers.







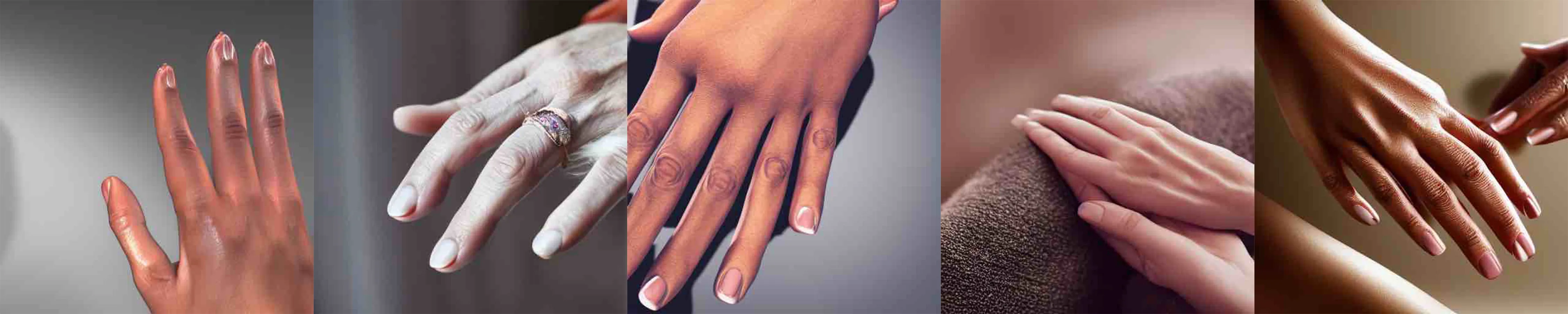

Traffic Light Prompts
We follow the same approach to attempt to improve the quality of generated images featuring traffic lights. In this case, we iteratively add more specificity regarding the desired output while considering the words, combinations, orderings, and punctuation that produce the lowest uncertainty. Several of the prompts considered are listed below along with some images generated using the lowest and highest scoring prompts. We can see some improvements when using prompts with lower risk scores. It is likely that continuing this process might lead to prompts that successfully depict traffic lights of a particular type.









Future Work
Several aspects of the Stable Diffusion implementation considered were not covered during our preliminary tests. For example, we have not attempted wrapping the Image Encoder, i.e., the model used when an image is included in the input along with the text prompt. We have also yet to explore the usage of negative prompts and their effects on uncertainty estimates. Another interesting preliminary test could be to track the epistemic uncertainty estimates obtained from decoding latents at each diffusion step. This would allow us to investigate the relationship between diffusion and decoding uncertainty throughout the entire generation process. Additionally, it is possible to use Capsa to estimate representation bias and aleatoric uncertainty in widely used image-text datasets. Finally, we plan to train the wrapped models with Capsa and to compare them with their original versions.
We will share more details on risk metric evaluation in a future blog post.
This post summarizes work published as “Risk-Aware Image Generation by Estimating and Propagating Uncertainty” (Perez et al., ICML 2023 Workshop on Challenges in Deployable Generative AI).